
What are the components of a GenAI technology stack that an organisation needs to consider?
This article breaks down the potential layers required in building a stack for an organisation. It simplifies the explanation of this so it’s suitable for CEO’s, CMO’s, AI Consultants etc.
If you want to just crack open ChatGPT and get your employees using it there’s a lot of benefit to doing this.
But if you’re a larger organisation that wants to have more control over the responses you will have to consider adding a couple of layers onto your stack.
You might want to build the product internally or use products that come with the technology stack you need (e.g. Microsoft CoPilot).
In this article we outline this technology stack so you have better knowledge of what is required behind the scenes to deliver a better system for your organisation.
So why not just use the ChatGPT application?
That is a good option for many businesses.
You can use ChatGPT and over time get better with the prompts.
Also ChatGPT (or similar tools) will evolve over time and start learning more about you and your organisation to give you better responses.
They will also have better controls in place to ensure better responses are coming back.
But you may want to jump a head of your competitors
Add a layer of knowledge onto the requests and responses…
Add a layer of analysis to the request and responses..
Even add a layer of security!!!
The Generative AI Technology Stack
The following shows the layers of a GenAI technology stack. This may be adapted depending on the complexity of what you want to implement but it will give you a good idea of the layers involved.

Let’s explain from the bottom up.
Infrastructure
GenAI uses vast volumes of data and we need to be able to store and process this data…
…And we are very impatient beings so it needs to be mega fast.
Wherever the model is stored and where requests are processed you’re going to need mega fast chips!
1 Trillion dollars in investment going into data centres over the next few years to deal with AI
Jason Huang – NVIDIA
NVIDIA have built an AI platform which they claim is that it’s the most advanced AI platform ever built. And they have really fast chips to go along with it…….

The market believes that they are going to do well with this platform….

Data Layer
The data layer of a foundation model is concerned with:
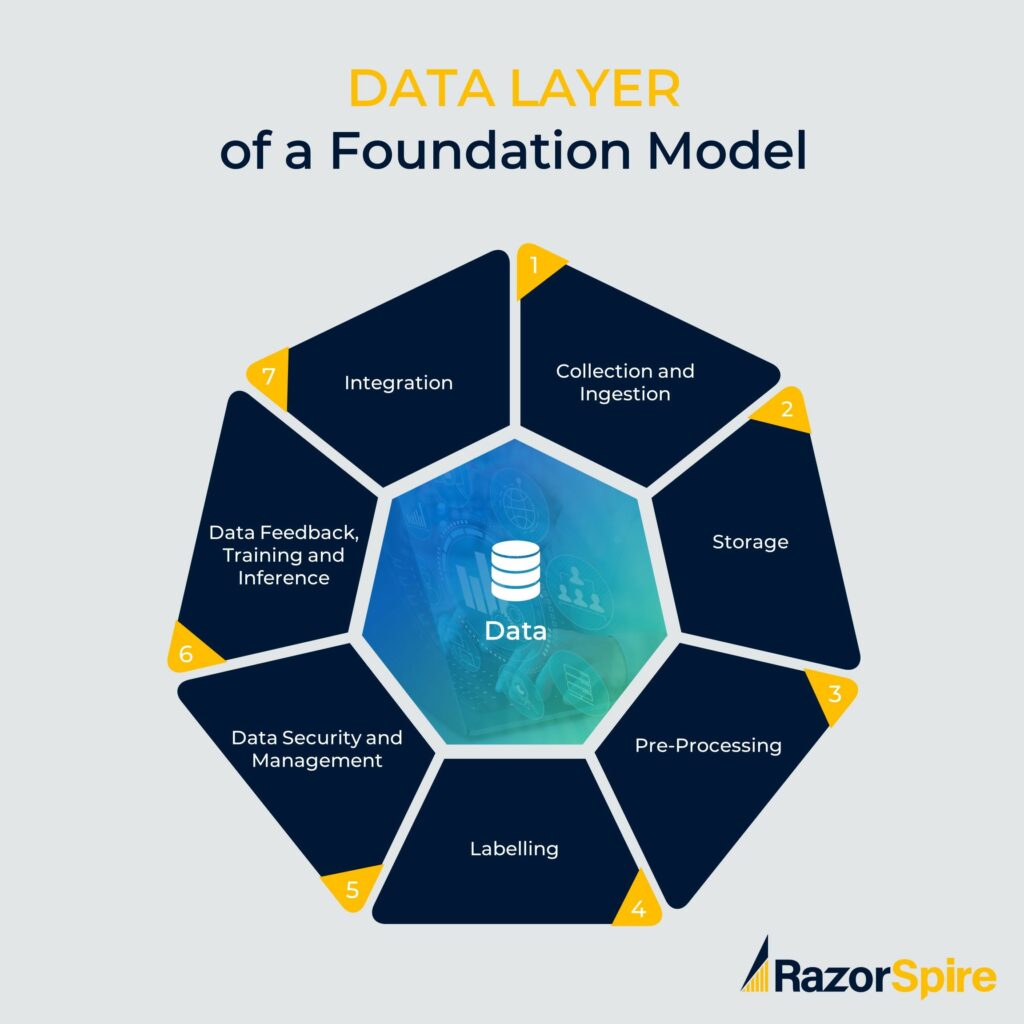
- Data Collection – You need to collect data from various sources e.g. web scraping, user generated content, publicly available data etc.
- Data Storage – Data needs to be store, for example, in databases. And you need to be able retrieve this data mega fast!
- Data Preprocessing – Once you take in the data there’s some processing on this data. There may be errors in the data, duplicate date etc.
- Data Labelling – Supervised learning is where the data is labelled instead of the model figuring out all the data itself. Labelling is describing what the parts of the data is about.
- Data Versioning and management – Your data will evolve over time so you need to understand what version of data you were using at any particular point in time.
- Data security and privacy – You need to ensure that data is protected at all time. Some regulations should as GDPR (European data protection legislation) need to be adhered to.
- Data feeds for training and inference – The data layer needs to be able to provide feeds of data to the model for training and inference. Inference is when the model is doing the work after it is trained!
- Integration layer – The data layer needs seamless integration with the relevant model.
Model Layer
This is where data is transformed into insights or actions. This layer can consist of one more models.
You can decide on the following:
| Type | Explanation |
| Open Source | A model provided for free where you are free to adjust |
| Closed Source | A model typically accessed via an API key. There is no ability to adjust the model |
| Proprietary | A model you have built yourself. This could be used internally only or provided as closed or open source model. |
Building your own model would require massive investment so this is probably not the option you’ll want to go for.
An open source model gives you greater flexibility but you’ll need to set up you own infrastructure to run is.
A closed source model doesn’t give you as much flexibility but you don’t have the worry about the infrastructure of the maintenance of the model.
You could also end up with a combination of open and closed source!
Read our article on ‘Foundation model’s to understand more about the model types.
Knowledge Layer
Within an enterprise organisation there’s a vast amount of knowledge that can be used to enhance the answers provided to people querying a model. For example:
- Internal databases – This could include employee information, customer information, product inventories etc.
- Document repositories – You might have an internal knowledge base or wiki full of useful and relevant information.
- External data sources- There could be additional data that is really valuable but accessible externally. So you’d need to build integration (if not already built) to access this data.
An example of a knowledge layer is MIcrosoft Graph. CoPilot is Microsoft’s AI that is integrated with the suite of Microsoft Apps.
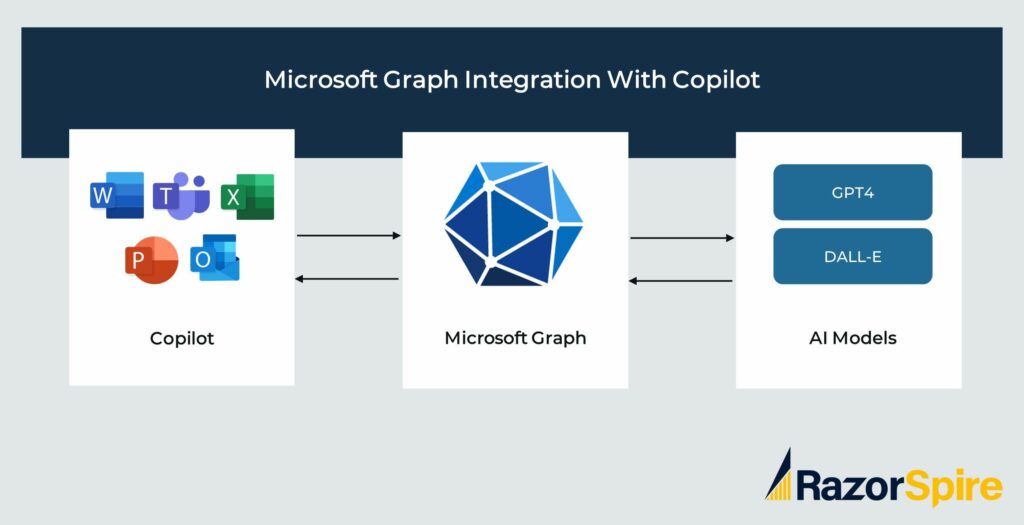
All requests coming from Microsoft Apps goes through Microsoft Graph which understands the user that is asking the question and has access to a lot of other information about the organisation.
The queries are adapted and passed to the foundation models GPT4 (mainly for text responses) or DALL-E (image responses). When the answers are sent back to Microsoft Graph there is some additional processing before responses are sent back to the applications.
Orchestration Layer
This is like a conductor in an orchestra!
It coordinates various components. For example:
- Integration with external systems – It manages integrations to CRM, ERP, CMS platforms etc.
- Enforcing security policies and compliance
- Managing workflows – Defining and executing workflows that automate tasks to prepare data, train models, deliver results etc.
- Model Selection – Automating the selection of the appropriate model
- Resource allocation – Allocating computational resources for different stages of the AI lifecycle.
- It manages data coming from different sources.
Microsoft Graph primarily sits in the knowledge layer but it does some orchestration where it can automate processes and integrate services.
Security and Compliance Layer
This can be embedded with in the orchestration layer or as a separate layer. It can be quite complex so it has advantages splitting it out.
- Security – Protect data, models and infrastructure from unauthorised access, breaches and cyber threats.
- Compliance – Adhering to laws, regulations and standards.
Application layer
This is the layer where the capabilities of the model are made accessible to users.
This is the interface used to query the model and get responses back.
Chatgpt is an application that sits within this layer.
CoPilot is also an application that sits in this layer.
Summary
Even though you may not be building a full Gen AI stack within your organisation it’s important to understand the components within an stack. I hope you find this article useful!
